💡 核心哲学:为了极大地降低命令行的记忆碎片,建议将精力投资在正则表达式与模糊匹配(如
fzf) 的通用语法上。掌握了这一套搜索逻辑,即可借助现代工具(fd/rg/fzf)通杀涵盖文件寻址、文本过滤、进程检索、甚至历史命令在内的 90% 日常场景,真正做到“一招吃遍天”。
目录结构
Linux 目录结构
1 | . |
查找命令
find
按条件递归查找文件和目录。
1 | find /path -name "*.log" # 按名称查找 |
💡 现代替代:fd — 语法更简洁,默认忽略
.gitignore,彩色输出。
1 | fd "\.log$" # 按正则查找 |
fzf
fzf 是一个宇宙级的通用终端模糊查找器。它不仅可以作为管道过滤器,本身更是命令补全和快捷跳转的外挂神器。
1. 基础管道与组合
1 | fzf # 独立运行:直接模糊搜索当前目录下所有文件 |
2. 快捷键触发(极力推荐配置)
安装 fzf 时如果写入了 shell 配置文件,将解锁三大灵魂快捷键:
Ctrl + R:历史命令搜索(彻底取代原生又丑又难用的reverse-i-search,大屏模糊匹配旧命令)。Ctrl + T:插入路径(在编写任何命令时按下,立刻搜索当前目录文件,回车后将路径自动贴入光标处)。Alt/Esc + C:神级跳转(按下立即搜索所有子目录,选中即可cd进入目标文件夹)。
3. Shell 终极补全 (**<TAB>)
在任意需要填入路径 / 进程号 / 主机的命令后输入 ** 并按下 Tab,可以直接触发全屏选择器供你“填空”:
1 | vim **<TAB> # 模糊搜索并打开深层文件 |
网络
状态与配置
ip
ip 命令用于管理网络接口、路由和地址,是 ifconfig、arp 和 route 的替代品。
1 | ip addr show # 查看所有网络接口及 IP |
ss
ss(Socket Statistics)用于查看网络连接、端口监听等信息。是 netstat 的替代品。
1 | ss -t # 查看所有 TCP 连接 |
nmcli
nmcli 是 NetworkManager 的命令行工具,主要用于管理网络环境(特别是终端连 Wi-Fi)。它比底层的 ip 命令更顶层,是以“连接(Connection)”和“设备(Device)”为核心逻辑的。
1 | nmcli general status # 查看 NetworkManager 运行状态 |
DNS 解析
dig
DNS 查询工具,用于调试 DNS 解析问题。是 nslookup 的替代品。
1 | dig example.com # 查询 A 记录 |
连通性与路由
ping
测试网络连通性和延迟。
⚠️ 注意:
ping基于 ICMP 协议,在某些网络下可能会被防火墙拦截。同时,许多服务器为防扫描会主动关闭 ping 响应(丢弃 ICMP 请求)。因此,ping不通不能作为判断服务宕机的唯一标准,建议结合curl/httpie、nc/nmap/telnet等工具综合测算端口连通性。
1 | ping example.com # 基本 ping |
traceroute
与 ping 都是基于 ICMP 协议,追踪数据包到目标主机经过的路由路径。
1 | traceroute example.com # 追踪路由 |
mtr
网络诊断和路由追踪的终极利器。它将 ping 和 traceroute 的功能结合在一起,动态实时显示每一跳路由的延迟和丢包率,是排查网络节点的首选工具。
1 | sudo mtr example.com # 启动交互式动态路由追踪(需要 root 权限) |
查看 mtr 结果时,以最后一跳的丢包率为准。
ping.pe
ping.pe 是一款全球多节点在线 Ping 与 MTR 路由追踪测试工具。它不仅能快速检测 IP 或域名在全球各地的连通性、延迟与丢包率,更是排查 GFW(防火长城)网络封禁状态的探针神器:
- IP 封禁(强阻断):若国内所有探测节点全部飙红(100% 丢包无法连通),而海外节点全绿,说明该 IP 已被重点“照顾”,只能尝试更换 IP。
- 端口封禁(精准阻断):若国内节点的 Ping 测试(ICMP 协议)一切正常,但在指定的业务端口连通性测试中惨遭阻断,说明仅端口被墙,为服务更换其他不敏感的端口即可恢复。
容器
/var/lib/docker/containers/[hash_of_the_container]/目录下的hostconfig.json和config.v2.json记录了容器的网络配置信息,修改此处即可修改容器的端口映射。
终端 IP 归属地查询
纯命令行调用的 IP 地址查询工具,排版极度舒适,常用于验证当前的终端全局代理(setproxy)是否成功生效。
1 | # cip.cc (国内最推荐,全中文排版显示 国家/省市/运营商) |
端口探测与扫描
telnet
最经典、最基础的测试目标主机特定 TCP 端口是否开放的工具。推荐用 nc 或 nmap 替代。
1 | telnet example.com 80 # 测试目标 80 端口连通性 |
nmap
强大的网络探测和安全扫描工具,常用于发现网络上的主机和服务,获取主机开放端口、操作系统指纹等。
💡 能力覆盖:
nmap实际上可以作为ping(仅用于探活时:-sn)、telnet/nc(仅用于测试端口开闭时:-p)、arp(查询局域网被占用的 IP)的强大平替或进阶补充方案。
1 | nmap example.com # 扫描常规的前 1000 个端口 |
⚠️ 防火墙陷阱(False Positive):很多云服务器的 WAF / 高防网关会对常见端口进行 “TCP 代理代答”,导致外网探测(如 nmap、telnet)显示端口 open,但本地 ss -lntp 却查无此进程。 此时可切到服务器终端扫本地环回地址(nmap -p 端口号 127.0.0.1),本地扫出来没开,那就是上游网络设备在代答,系统本身非常安全。
nc
nc(netcat)是网络调试的瑞士军刀,可用于端口扫描、传输数据、建立连接等。
1 | nc -zv example.com 80 # 端口扫描 |
HTTP 通信与传输
curl
用于发送 HTTP 请求和传输数据的命令行工具。
1 | curl https://example.com # GET 请求 |
💡 现代替代:httpie — 更人性化的语法,自动 JSON 高亮。
1 | http GET https://api.example.com # GET 请求 |
wget
最经典、且极度坚韧的文件下载利器。与 curl 偏向于测试 API 和发送数据不同,wget 专精于大文件下载、断点续传以及整站扒取。
1 | wget https://example.com/file.zip # 基本用法:下载文件到当前目录 |
远程传输与备份
rsync
rsync 降维打击了 scp 和 cp -r,核心优势是智能比对哈希差异,只通过网络传输发生变动的几十 KB 碎片(增量同步),是处理大文件集群拷贝的终极方案。
1 | # 基本拷贝(完全替代 cp -r) |
⚠️ 路径结尾带不带
/可是天壤之别!
比如你想传一整个相册:rsync -a /photo会在对面建一个叫photo的外壳文件夹;而如果多敲了一个斜杠:rsync -a /photo/,它就像是“解压缩”一样,只会把相册里的照片全倒在对面的目标地里,不建外壳!
终端网络代理
纯底层的终端程序(如 curl、git、brew、nmap)默认不会读取 macOS 系统设置的全局代理或 PAC 规则。它们极其“固执”,只认当前 Shell 进程内的专属环境变量。
为了更优雅地在使用代理软件(如 Clash)时动态接管终端流量,建议在 ~/.zshrc (或 bashrc) 中添加以下快速开关别名(假设本地代理软件的混淆端口为默认的 7890):
1 | # ~/.zshrc 配置 |
⚠️ 注意:
像ping、traceroute和mtr等底层排障工具走的是 ICMP 网络层(L3)协议。而常见的代理软件一般只能接管 TCP/UDP 即应用层/传输层(L4~L7)的流量。
因此不要指望开启终端代理后能用ping成功连通外网,常规代理对ping是绝对免疫且无效的,测试代理连通性请务必使用curl -I google.com等 HTTP 替代方案!
文件查看
cat
查看文件内容。
1 | cat file.txt # 查看文件 |
💡 现代替代:bat — 语法高亮、行号、Git diff 标注、自动分页。
1 | bat file.py # 语法高亮查看 |
ls
列出目录内容。
1 | ls -a # 列出所有文件(含隐藏文件) |
💡 现代替代:eza — 彩色图标、Git 状态集成、树形视图。
1 | eza -la # 列出所有文件(含隐藏) |
可用 Rust 实现的 eza 替代 Ruby 实现的 colorls
yazi
yazi 是当前终端界最火的全异步、极限性能的 TUI 文件管理器(同样由 Rust 编写)。它完美继承并彻底超越了老旧的 ranger,是现代终端文件管理的最终答案。
💡 神级特性:原生支持终端内超清渲染图片和视频预览;与
fzf、zoxide、rg深度融为一体;拥有极其强大的并发大文件拷贝/删除 I/O 能力。
1 | yazi # 启动文件大盘管理器 |
文本处理
匹配与搜索
grep
在文件中搜索匹配的文本模式。
1 | grep "pattern" file.txt # 基本搜索 |
💡 现代替代:ripgrep (rg) — 比 grep 快数倍,默认递归、自动忽略
.gitignore。
1 | rg "pattern" # 自动递归搜索当前目录 |
提取与切分
cut
按列(字段)提取文本。
1 | cut -d: -f1 /etc/passwd # 提取用户名 (按分隔符提取指定字段) |
awk
强大的文本处理语言,擅长按列处理结构化文本。
1 | awk '{print $1}' file.txt # 第 1 列 (打印指定列) |
排序与去重
sort
对文本行进行排序。
1 | sort file.txt # 默认排序(字典序) |
uniq
去除或统计连续的重复行(通常与 sort 搭配使用)。
1 | sort file.txt | uniq # 去除连续重复行 |
统计与对比
wc
统计文件的行数、单词数和字节数。
1 | wc -l file.txt # 统计行数 |
diff
比较两个文件的差异。
1 | diff file1.txt file2.txt # 基本对比 |
💡 现代替代:delta — 语法高亮的 diff 工具,可作为 Git pager。
1 | delta file1.txt file2.txt # 对比两个文件(语法高亮) |
流编辑与替换
sed
流编辑器,用于对文本进行替换、删除、插入等操作。
1 | sed 's/old/new/' file.txt # 替换第一个匹配 |
格式化与参数转换
jq
命令行 JSON 处理器,用于解析、过滤和转换 JSON 数据。
1 | echo '{"name":"foo","age":30}' | jq '.' # 格式化 JSON |
xargs
将标准输入转换为命令行参数,常配合管道使用。
1 | echo "file1 file2 file3" | xargs rm # 基本用法 |
进程与系统
系统信息
1 | lscpu # 查看 CPU 架构、核心数等详细物理硬件信息 |
systemctl
systemctl 是 systemd 的核心指令,用于管理系统服务(Services)、服务自启及其状态大盘。
1 | systemctl status nginx # 查看服务当前状态和最近几条启动报错日志 |
💡 最佳搭档
journalctl:由于 systemd 会统一接管所有服务的控制台输出格式,你可以直接用配套工具极速排查日志:
journalctl -u nginx -f:像tail -f一样实时滚动查看指定服务的控制台输出。journalctl -u nginx --since "1 hour ago" -e:查看该服务最近一小时的日志并直接翻到最后。
自定义服务(.service 文件)
将自己的程序注册为系统服务,需要在 /etc/systemd/system/ 下创建一个 .service 文件:
1 | # /etc/systemd/system/my-app.service |
写完后的标准注册流程:
1 | sudo systemctl daemon-reload # 必须先重载,让 systemd 识别新文件 |
定时任务(.timer 文件)
.timer 是 systemd 的内置定时器,用来替代传统的 cron,可以按固定时间或开机后延迟触发另一个 .service。.timer 和 .service 文件必须同名配对使用(如 backup.timer 驱动 backup.service):
1 | # /etc/systemd/system/backup.service (被 timer 触发的实际任务) |
1 | # /etc/systemd/system/backup.timer (定时触发器) |
常用的 OnCalendar 时间表达式:
1 | OnCalendar=hourly # 每小时 |
systemd 默认给所有的 Timer 设置了
AccuracySec=1min,这意味着:系统保证任务会在 00:00:00 到 00:01:00 这个区间内的某个随机时刻执行,而不是精确在第 0 秒。如果需要精确到秒,可以设置AccuracySec=1s。
启用定时器(只需 enable timer,不需要 enable service):
1 | sudo systemctl daemon-reload |
.service vs .timer 选型指南
| 场景 | 选择 |
|---|---|
| 需要持续运行的后台进程(Web 服务、数据库、代理) | 只写 .service |
| 需要定时执行一次性任务(备份、清理、同步) | .service(Type=oneshot)+ .timer |
原本用 cron 的场景 |
迁移到 .timer,可获得日志追踪和错过补跑能力 |
💡 为什么用
.timer而不是cron?systemd timer的所有执行记录都会被journalctl统一收集,可用journalctl -u backup.service随时追溯历史运行结果;而传统cron的输出默认只发邮件或直接丢弃,调试极其痛苦。
sysctl
sysctl 用于在运行时读取或修改 Linux 内核参数(位于 /proc/sys/ 下),是服务器调优和代理/转发类服务部署的必备工具。
1 | sysctl -a # 查看所有内核参数(输出量极大,建议配合 grep 过滤) |
永久生效:将参数写入
/etc/sysctl.d/下的配置文件,然后用sysctl --system重载:
2
3
echo "net.ipv4.ip_forward = 1" | sudo tee /etc/sysctl.d/99-custom.conf
sudo sysctl --system # 重载所有 /etc/sysctl.d/*.conf 配置文件
常用内核参数速查
1 | # ── IP 路由转发(部署 VPN / Hysteria2 端口跳跃 / Docker 必须开启)── |
应用 BBR 后可用
sysctl net.ipv4.tcp_congestion_control确认是否已切换成功。
ps
查看正在运行的进程。
1 | ps aux # 查看所有进程(详细信息) |
看资源占用率用
ps aux,看父子关系链用ps -ef。
💡 现代替代:procs — 彩色输出,支持关键字搜索、树形视图。
1 | procs # 查看所有进程 |
top
实时查看系统资源占用和进程信息。
1 | top # 启动交互式监控 |
💡 现代替代:btop — 美观的全功能系统监控,支持 CPU/内存/网络/磁盘图表。
1 | btop # 启动交互式系统监控 |
个人环境推荐使用
btop,生产环境可以使用top/htop, 它们不挑剔环境。
du
查看文件和目录的磁盘占用。
1 | du -sh . # 查看当前目录的总大小 |
💡 现代替代:dust — 可视化条形图展示磁盘占用。
1 | dust # 当前目录的磁盘占用可视化 |
df
查看磁盘分区的使用情况。
1 | df -h # 查看所有挂载点的磁盘使用 |
💡 现代替代:duf — 表格化彩色展示。
1 | duf # 全部磁盘信息 |
ncdu
ncdu(NCurses Disk Usage)是一个终端交互式磁盘占用分析工具,比 du 更直观,可以用键盘浏览目录并快速定位占用空间最大的文件。
1 | ncdu # 分析当前目录 |
界面内按
d可删除选中文件或目录,?查看帮助,q退出。
辅助工具
man
查看命令手册。
1 | man ls |
💡 现代替代:tldr — 简洁实用的命令示例,告别冗长的 man 手册。
1 | tldr tar # 查看 tar 的常用示例 |
cd
切换工作目录。
1 | cd /path/to/dir |
💡 现代替代:zoxide — 智能目录跳转,自动学习你最常访问的目录。
1 | z foo # 跳转到最常用的含 "foo" 的目录 |
zellij
Zellij 是下一代终端多路复用器(Terminal Multiplexer)。完全采用 Rust 编写,旨在取代老旧、配置繁琐的 tmux。它开箱即用,带有极其现代化的 UI、原生鼠标支持和悬浮窗功能。
💡 核心优势:0 学习成本,所有快捷键都常驻显示在底部的状态栏面板上,支持真正的浮动窗口(Floating Panes)以及 WebAssembly 插件生态。
1 | zellij # 启动一个全新的 zellij 会话 |
防火墙
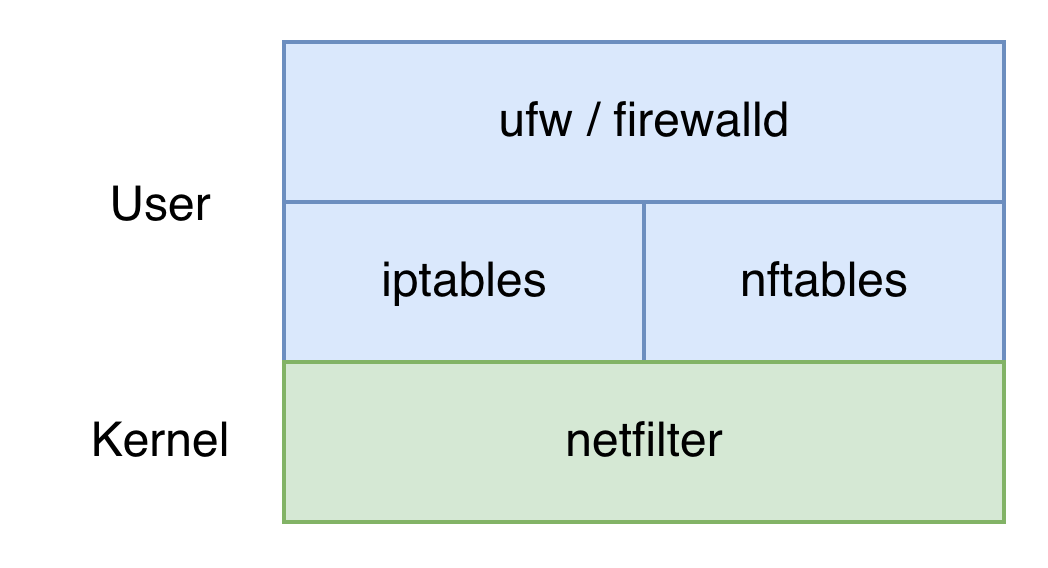
如图所示,Linux 中提供了多种防火墙工具,最上层是不同 Linux 发行版本提供的防火墙管理工具,可以简单设置防火墙规则;中间是内核的接口层,具有很强的灵活性和精细的控制能力,iptables 已经被 nftables 取代;最下层是 netfilter,是 Linux 内核中的防火墙。
注意:不能启动任何两种以上的防火墙,否则防火墙间的冲突会令人很困惑,增加排障难度。
iptables
iptables 底层调用netfilter,但由于 已经被 nftables 取代,目前仍有需要系统使用 iptables,只需要能够读懂即可。
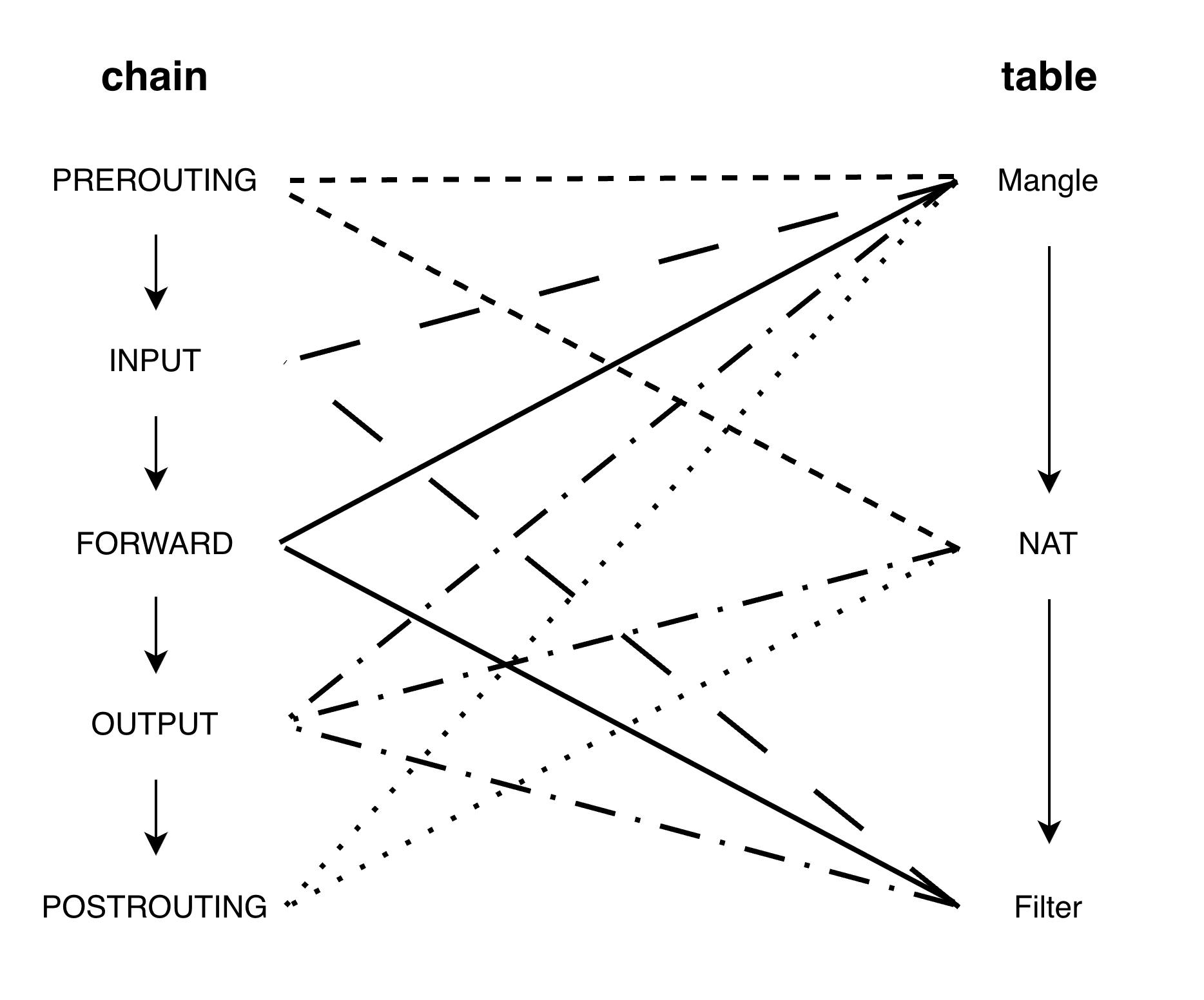
语法规则:
1 | iptables [-[ADI] INPUT] [-i lo|eth0|ens3] [-s IP/Netmask] [-d IP/Netmask] [-p tcp|udp [--sport ports] [--dport ports]] [-j ACCEPT|REJECT|DROP] |
-t <table_name>:指定操作的表(如filter、nat、mangle),缺省状态下默认是filter表。-A <chain_name>:Append,表示在指定的链(如INPUT、POSTROUTING)的最后面追加一条新规则。同理还有-I(Insert,插入到规则的最前面)和-D(Delete,删除该规则)。-p <protocol>:匹配特定协议类型,例如tcp、udp、icmp等。-s/-d:分别匹配源(Source)IP / 目标(Destination)IP 或网段。--sport/--dport:分别匹配源端口 / 目标端口(使用前通常必须配合-p指定具体协议)。-i/-o:分别匹配数据包流入的网卡接口(in-interface,如eth0)和流出的网卡接口(out-interface)。-j <target>:Jump,决定当包被该规则匹配上之后的最终动作。常见的有ACCEPT(放行)、DROP(直接丢弃报文)、REJECT(拒绝并返回一个错误包给发送方)、SNAT以及DNAT等。
常用命令:
1 | # 查看规则 |
ufw
ufw(Uncomplicated Firewall)是 Ubuntu/Debian 系统上的简化防火墙管理工具。
1 | sudo ufw enable # 启用/禁用防火墙 |
nft
nft (nftables) 是 iptables 的现代替代品,提供了一个更简单、更高效的结构化规则框架,用来统一管理网络过滤、地址转换(NAT)等功能。
常用命令
1 | nft list ruleset # 查看全系统所有规则(等同于 iptables-save) |
💡 最佳实践:不要在命令行中一行行敲
nft动态添加规则!nftables最优雅的用法是将其看作类似 Nginx 的配置文件,在一个文件(如/etc/nftables.conf)中写好结构化的规则,然后使用nft -f /etc/nftables.conf原子级重新加载生效。
nft 与 ufw / iptables 的区别
- ufw (Uncomplicated Firewall):本质上是一个前端包装器。它的存在是为了让小白用极其简单的命令(如
ufw allow 22)来配置防火墙。在较老的系统上它底层调用的是iptables,在较新的 Ubuntu 系统上它底层实际调用的正是nftables。 - iptables:古典时代的防火墙霸主。缺点是规则呈现链表式线性匹配(规则越多性能越差),而且 IPv4(
iptables)和 IPv6(ip6tables)必须写两套配置,目前已被 Linux 内核官方标记为过时(废弃)。 - nftables (nft):Linux 官方的新一代网络过滤框架底座。支持在一个
inet表中同时处理 IPv4 和 IPv6 ;支持集合(Sets)和字典映射合并规则;底层原理修改为了类似于伪状态机的字节码,执行和匹配效率极高;语法更加现代化。
注意事项
- Docker 穿透防火墙的经典大坑:由于 Docker 的端口映射逻辑是直接往系统底层的
NAT 表(PREROUTING 链)里注入路由转发规则,其优先级处于系统网络栈的最前端。这意味着:哪怕你用ufw deny 80封锁了 80 端口,只要你用docker run -p 80:80启动了容器,外网依然可以畅通无阻地访问该容器!解决方案:发布 Docker 服务时,端口映射写死本机回环地址
127.0.0.1:80:80(仅允许本地访问),然后通过本机的 Nginx 等反向代理转发并暴露到公网,将访问控制权交还给安全的代理层或原生的主机防火墙。 - 规则持久化:直接在终端敲
nft add临时加入的规则保存在内存中,重启系统就会丢失。必须将最终生效的规则通过nft list ruleset > /etc/nftables.conf导出保存,并确保systemctl enable nftables服务开机时自动从该文件重载。 - 不要混用管理工具:如果你决定用
ufw,就彻底忘掉iptables和nft命令;如果你觉得ufw太简陋决定手搓nftables.conf,就必须先把ufw彻底disable。同时混用两大前端管理工具会导致底层链表交火,轻则网络不通,重则把你自己的 SSH 远程连接锁死在服务器门外。
根据所处的发行版,关闭原有的防火墙管理服务:
1 | # 1. 停止 ufw (主要针对 Ubuntu/Debian) |